RS矩阵分解 概述
源自于评分预测问题。评分预测问题很典型但是并不大众,与之相对的另一类问题行为预测,才是平民级推荐问题,处处可见。
为什么要矩阵分解
矩阵分解确实可以解决一些近邻模型无法解决的问题。
近邻模型存在的问题:
- 物品建存在相关性,信息量并不随着向量维度增加而线性增加。
- 矩阵元素稀疏,计算结果不稳定,增减一个向量维度,导致近邻结果差异很大的情况存在。
上述两个问题,在矩阵分解中可以得到解决。矩阵分解,直观上说来简单,就是把原来的大矩阵,近似分解成两个小矩阵的乘积,在实际推荐计算时不再使用大矩阵,而是使用分解得到的两个小矩阵。
具体说来就是,假设用户物品的评分矩阵A是m乘以n维,即共有m个用户,n个物品。我们选一个很小的数k,这个k比m和n都小很多,比如小两个数量级这样,通过一套算法得到两个矩阵U和V,矩阵U的维度是m乘以k,代表用户偏好的用户隐因子向量。矩阵V的维度是n乘以k,代表物品语义主题的隐因子向量。
矩阵UV需要能够通过公式复原矩阵A: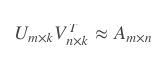
得到的这两个矩阵有这么几个特点:
1.每个用户对应一个k维向量,每个物品也对应一个k维向量,就是所谓的隐因子向量,因为是无中生有变出来的,所以叫做“隐因子”;
2.两个矩阵相乘后,就得到了任何一个用户对任何一个物品的预测评分,具体这个评分靠不靠谱,那就是看功夫了。就需要定义损失函数去优化。
所以说矩阵分解,所做的事就是矩阵填充。
基础的SVD算法
SVD全称奇异值分解,属于线性代数的知识,在推荐算法中实际使用的并不是正统的奇异值分解,而是一个伪奇异值分解。传统SVD在实际应用场景中面临着稀疏性问题和效率问题。所以,提出了一个新的方法Funk-SVD算法,其主要思路是将原始评分矩阵M(m*n)分解成两个矩阵P(m*k)和Q(k*n),同时仅考察原始评分矩阵中有评分的项分解结果是否准确,而判别标准是均方差。这种方法被称为隐语义模型(Latent factor)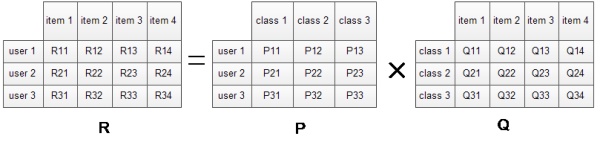
用户评分矩阵通常是稀疏的,如果只有少数项有值,极易造成过拟合,此时就要通过矩阵分解将矩阵分解为稠密的矩阵。矩阵分解,就是把用户和物品都映射到一个k维空间中,这个k维空间不是我们能直接看到的,也不一定具有非常好的可解释性,每一个维度也没有名字,所以常常叫做隐因子,代表藏在直观的矩阵数据下。
每一个物品都获得一个向量q,每一个用户也得到一个向量p。
对于物品,与它对应的向量q中的元素有正有负,代表这个物品背后隐藏的一些用户关注的因素。
对于用户,与它对应的向量p的元素,也有正有负,代表这个用户在若干因素上的偏好。物品被关注的因素,和用户偏好的因素,它们的数量和意义是一致的,就是矩阵分解之初人为指定的k。
例如,用户u的向量是pu,物品i的向量是qi,要计算物品i推荐给用户u的推荐分数,直接计算点积即可: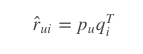
难点在于,如何得到每一个用户,每一个物品的k维向量。这是一个机器学习问题。两个要素,损失函数和优化算法。
SVD的损失函数定义如下: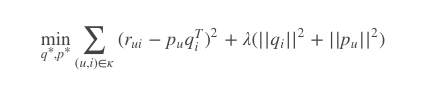
加号前一部分控制着模型的偏差,加号后一部分控制着模型的方差。
前一部分就是用分解后的矩阵预测分数,要和实际的用户评分之间误差越小越好。后一部分就是,得到的隐因子向量要越简单越好,以控制这个模型的方差,也就是让它在真正执行推荐任务时要发挥稳定,以免产生“过拟合”。
整个SVD的学习过程就是:
- 准备好用户物品的评分矩阵,每一条评分数据看做一条训练样本。
- 给分解后的U矩阵和V矩阵随机初始化元素值。
- 用U和V计算预测后的分数。
- 计算预测的分数和实际的分数误差。
- 按照梯度下降的方向更新U和V中的元素值。
- 重复步骤3到5,直到到达停止条件。
得到分解后的矩阵之后,实质上就是得到了每个用户和每个物品的隐因子向量,拿着这个向量再做推荐计算就简单了。
增加偏置信息
实际情况下,一些用户会给出偏高的分数,比如标准宽松的用户,有些物品也会受到偏高的评分,比如一些目标观众为铁粉的电影,甚至有可能整个平台的全局评分就偏高。
原装的SVD就有了第一个变种:把偏置信息抽出来的SVD。
一个用户给一个物品的评分会由四部分相加:
从左至右分别代表:全局平均分、物品的评分偏置、用户评分的偏置、用户和物品之间的兴趣偏好。
针对前面三项偏置分数,我在这里举个例子,假如一个电影评分网站全局平均分是3分,《肖申克的救赎》的平均分比全局平均分要高1分。
你是一个对电影非常严格的人,你一般打分比平均分都要低0.5,所以前三项从左到右分别就是3, 1, -0.5。 如果简单的就靠这三项,也可以给计算出一个你会给《肖申克的救赎》打的分数,就是3.5。
增加了偏置信息的SVD模型目标函数稍有改变:
和基本的SVD相比,要想学习两个参数:用户偏置和物品偏置。学习的算法还是一样的。
增加历史行为
相比沉默的大多数,主动点评电影或者美食的用户是少数。也就是显示反馈比隐式反馈少,但是可以利用隐式反馈来弥补这一点,对于用户的个人属性,比如性别,也可以加入到模型中来弥补冷启动的不足。
在SVD中结合用户的隐式反馈行为和属性,这套模型叫做SVD++。
加入隐式反馈的方法是除了假设评分矩阵中的物品有一个隐因子向量外,用户有过行为的物品集合也都有一个隐因子向量,维度是一样的。把用户操作过的物品隐因子向量加起来,用来表达用户的兴趣偏好。
综合两者,SVD++的目标函数中,只需要把推荐分数预测部分稍作修改,原来的用户向量部分增加了隐式反馈向量和用户属性向量。
学习算法依然不变,只是要学习的参数多了两个向量: x和y。其中N(U)表示为用户U提供了隐式反馈的物品的集合。xi所在的项是隐式反馈的物品向量,ya所在的项是用户属性的向量。这样一来,在用户没有评分时,也可以用他的隐式反馈和属性做出一定的预测。
考虑时间因素
人是善变的,今天的我们和十年前的我们很可能不一样了,在SVD中考虑时间因素也变得顺理成章。
在SVD中考虑时间因素,有几种做法:
1.对评分按照时间加权,让久远的评分更趋近平均值;
2.对评分时间划分区间,不同的时间区间内分别学习出隐因子向量,使用时按照区间使用对应的隐因子向量来计算;
3.对特殊的期间,如节日、周末等训练对应的隐因子向量。
交替最小二乘原理(ALS)
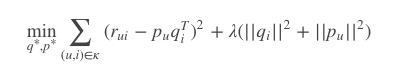
有了目标函数,就要用到优化算法找到使它最小的参数,优化算法常用的有两个,一个是随机梯度下降(SGD),是针对qi或者pu整条向量进行更新而不是单个元素。
损失函数求偏导: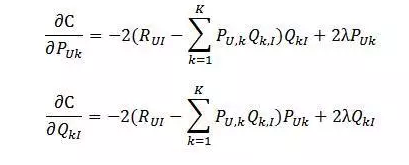
根据随机梯度下降法得到的递推公式: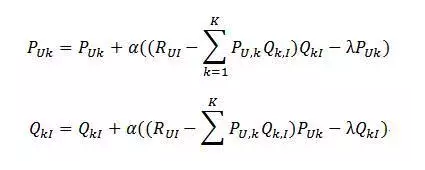
另一个是交替最小二乘(ALS)。
在实际应用中,交替最小二乘更常用一些,这也是社交巨头Facebook在他们的推荐系统中选择的主要矩阵分解方法。
交替最小二乘的核心是交替,任务是找到两个矩阵P和Q,让它们相乘后约等于原矩阵R: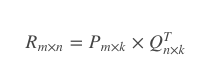
如果知道其中一个,那另一Q也就已知了,交替最小二乘法通过迭代解决了这个鸡生蛋蛋生鸡的问题。
1.初始化随机矩阵Q里面的元素值;
2.把Q矩阵当做已知的,直接用线性代数的方法求得矩阵P;
3.得到了矩阵P后,把P当做已知的,故技重施,回去求解矩阵Q;
4.上面两个过程交替进行,直到目标函数可以接受为止。
交替最小二乘的好处:
1.在交替的其中一步,也就是假设已知其中一个矩阵求解另一个时,要优化的参数是很容易并行化的;
2.在不那么稀疏的数据集合上,交替最小二乘通常比随机梯度下降要更快地得到结果。
隐式反馈
矩阵分解算法,是为解决评分预测问题而生的,然而事实上却是,用户首先必须先去浏览商品,然后是购买,最后才可能打分。相比“预测用户会打多少分”,“预测用户会不会去浏览”更加有意义,而且,用户浏览数据远远多于打分评价数据。也就是说,实际上推荐系统关注的是预测行为,行为也就是一再强调的隐式反馈。
最方便的数据时高质量的显式反馈,其中包括用户对产品感兴趣的显式输入。通常,显式反馈包含一个稀疏矩阵,因为任何一个用户可能只对可能的项目进行了一小部分的评分。隐式反馈通常指示一个事件存在或不存在,因此它通常由一个密集的矩阵表示。
如果把预测用户行为看成一个二分类问题, 猜用户会不会做某件事,但实际上收集到的数据只有明确的一类:用户干了某件事,而用户明确“不干”某件事的数据却没有明确表达。所以这就是One-Class的由来,One-Class数据也是隐式反馈的通常特点。
对隐式反馈的矩阵分解,需要将交替最小二乘做一些改进,改进后的算法叫做加权交替最小二乘: Weighted-ALS。
用户对物品的反馈,通常是多次的,行为的次数是对行为的置信度反应,也就是所谓的加权。
加权交替最小二乘法对待隐式反馈:
1.如果用户对物品无隐式反馈则认为评分是0;
2.如果用户对物品有至少一次隐式反馈则认为评分是1,次数作为该评分的置信度。
现在的目标函数变为: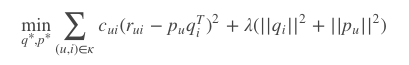
多出来的Cui就是置信度,在计算误差时考虑反馈次数,次数越多,就越可信。置信度一般也不是直接等于反馈次数,根据一些经验,置信度Cui这样计算: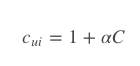
其中阿尔法是一个超参数,需要调教,默认值取40可以得到差不多的效果,C就是次数了。
此时那些没有反馈的缺失值,就是在我们的设定下,取值为0的评分就非常多,有两个原因导致在实际使用时要注意这个问题:
1.本身隐式反馈就只有正类别是确定的,负类别是我们假设的。
2.这会导致正负类别样本非常不平衡,严重倾斜到0评分这边。
应对这个问题的做法就是负样本采样:挑一部分缺失值作为负类别样本即可。有两种挑的方法。
1.随机均匀采样和正类别一样多。
2.按照物品的热门程度采样。
在实践中,第一种不是很靠谱,第二种经受住了检验,其思想是一个越热门的物品,用户越可能知道它的存在。那这种情况下,用户还没对它有反馈就表明:这很可能就是真正的负样本。
推荐计算
在得到了分解后的矩阵后,相当于每个用户得到了隐因子向量,这是一个稠密向量,用于代表他的兴趣。同时每个物品也得到了-个稠密向量,代表它的语义或主题。而且可以认为这两者是一一对应的,用户的兴趣就是表现在物品的语义维度上的。
看上去,让用户和物品的隐因子向量两两相乘,计算点积就可以得到所有的推荐结果了。但是实际上复杂度还是很高,尤其对于用户数量和物品数量都巨大的应用,如Facebook,就更不现实。于是Facebook提出了两个办法得到真正的推荐结果。
第一种, 利用一些专门设计的数据结构存储所有物品的隐因子向量,从而实现通过一个用户向量可以返回最相似的K个物品。Facebook给出了自己的开源实现Faiss,类似的开源实现还有Annoy, KGraph, NMSL IB。其中Facebook开源的Faiss 和NMSLIB (Non-Metric Space Library)都用到了ball tree来存储物品向量。
如果需要动态增加新的物品向量到索引中,推荐使用Faiss,如果不是,推荐使用NMSLIB或者KGraph。用户向量则可以存在内存数据中,这样可以在用户访问时,实时产生推荐结果。
第二种,就是拿着物品的隐因子向量先做聚类,海量的物品会减少为少量的聚类。然后再逐一计算用户和每个聚类中心的推荐分数,给用户推荐物品就变成了给用户推荐物品聚类。
得到给用户推荐的聚类后,再从每个聚类中挑选少许几个物品作为最终推荐结果。这样做的好处除了大大减小推荐计算量之外,还可以控制推荐结果的多样性,因为可以控制在每个类别中选择的物品数量。
矩阵分解的优缺点
矩阵分解有如下的优点:
- 能将高维的矩阵映射成两个低维矩阵的乘积,很好地解决了数据稀疏的问题;
- 具体实现和求解都很简洁,预测的精度也比较好;
- 模型的可扩展性也非常优秀,其基本思想也能广泛运用于各种场景中。
矩阵分解的缺点有:
- 可解释性很差,其隐空间中的维度无法与现实中的概念对应起来;
- 训练速度慢,很难实现实时推荐,不过可以通过离线训练来弥补这个缺点;
- 实际推荐场景中往往只关心topn结果的准确性,此时考察全局的均方差显然是不准确的。
矩阵分解作为推荐系统中的经典模型,已经经过了十几年的发展,时至今日依然被广泛应用于推荐系统当中,其基本思想更是在各式各样的模型中发挥出重要作用。但是对于推荐系统来说,仅仅有一个好的模型是远远不够的。影响推荐系统效果的因素非常之多。想要打造一个一流的推荐系统,除了一个强大的算法模型之外,更需要想方设法结合起具体业务,不断进行各种尝试、升级,方能取得最终的胜利。